Story Generation Results
Story Generation Results

Autoregressive models (ARMs) and diffusion models (DMs) represent two leading paradigms in generative modeling, each excelling in distinct areas: ARMs in global context modeling and long-sequence generation, and DMs in generating high-quality local contexts, especially for continuous data such as images and short videos. However, ARMs often suffer from exponential error accumulation over long sequences, leading to physically implausible results, while DMs are limited by their local context generation capabilities. In this work, we introduce Autoregressive Coherent multimodal generation with Diffusion Correction (ACDC), a zero-shot approach that combines the strengths of both ARMs and DMs at the inference stage without the need for additional fine-tuning. ACDC leverages ARMs for global context generation and memory-conditioned DMs for local correction, ensuring high-quality outputs by correcting artifacts in generated multimodal tokens. In particular, we propose a memory module based on large language models (LLMs) that dynamically adjusts the conditioning texts for the DMs, preserving crucial global context information. Our experiments on multimodal tasks, including coherent multi-frame story generation and autoregressive video generation, demonstrate that ACDC effectively mitigates the accumulation of errors and significantly enhances the quality of generated outputs, achieving superior performance while remaining agnostic to specific ARM and DM architectures.
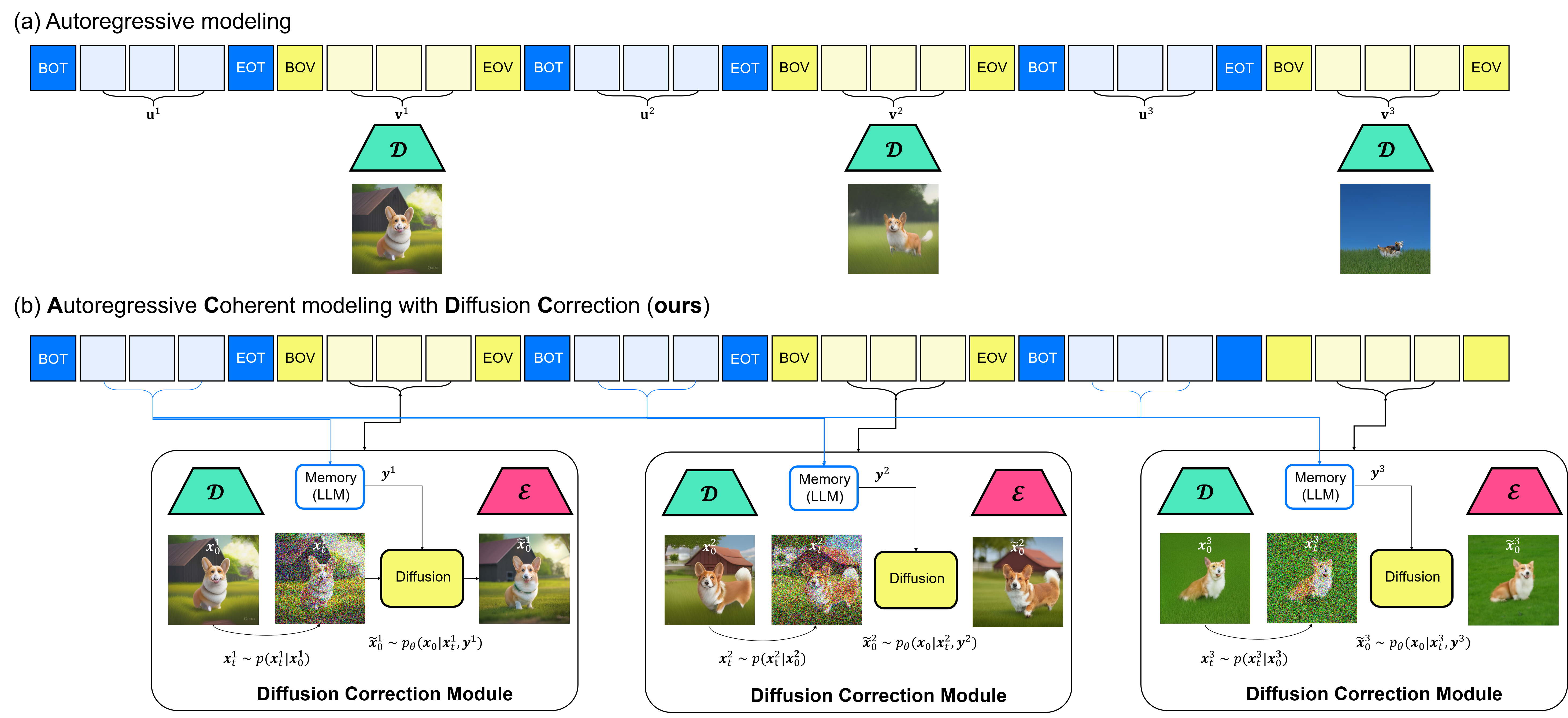
In autoregressive models (ARMs), decoded frames often exhibit visual artifacts, which are relatively minor in the initial frame but become more pronounced in later predicted frames due to error propagation. To address this, we propose ACDC, a versatile algorithm that leverages pretrained diffusion models (DMs) for localized correction of ARM-generated frames using a text-conditional SDEdit approach. After the correction, ACDC allows the ARM model to generate the subsequent frame, effectively mitigating error accumulation during inference and improving overall visual quality in generated sequences. This method can be seamlessly integrated into any ARM framework.

When processing individual frames, diffusion models (DMs) cannot infer local context from prompts like "His" without additional information. To address this limitation, we design and train a seperate memory module tailored for this task. Leveraging a large language model (LLM), we generate new prompts conditioned on the previous ones, ensuring that key contextual information is preserved throughout the sequence.


We observe that ACDC consistently generates more coherent content compared to the base ARM, maintaining the main character's appearance while allowing for dynamic changes in background and motion.

In our approach, we addressed the issue of physically incorrect images generated by the base ARM model by applying Stable Diffusion (SD) inpainting for correction. Our findings demonstrate that ACDC effectively mitigates the propagation of physical errors through this correction process.
Baseline
ACDC
Baseline
ACDC
A male interviewer listening to a person talking
A wooden house overseeing the lake
Baseline
ACDC
Baseline
ACDC
An elegant ceramic plant pot and hanging plant on indoor
A boat sailing on a stormy ocean
Baseline
ACDC
Baseline
ACDC
Aerial video of Stuttgart tv tower in Germany
A cute happy corgi playing in park, sunset
We demonstrate that in the video domain, ACDC effectively slows down error propagation after applying corrections, allowing for the generation of longer and more consistent video sequences compared to the base ARM.